
Your RCE use-case doesn't have to be a nightmare
Learnings from years of toy experiments and production meltdowns with code execution
RCE (Remote Code Execution) is pretty wicked. Not the scary CVE headlines, but the engineering gymnastics required to let strangers run code safely on your hardware.
How we got here
My obsession started back in university while building NextJudge with some of the best competitive programmers I know. Think Codeforces, but self-hosted and hackable.
NextJudge's very first AC (accepted submission) was add two numbers (linked list) done in C - because, of course, it was.
Other than that, I've spun up a small set of sandbox toys:
- God - a Docker orchestration playground
- Titan - a Go rewrite powered by Tork
- Assorted throw-away experiments that definitely ate too many CPU cycles
To summarize what I've learned: Spin containers fast, kill them faster, repeat.
God, for instance, keeps a pool of ready-to-go containers and hand-picks one at random for each submission.
This matters later. First, here's how I got it working.
Tork
Tork is an open-source workflow engine that I came across. Written in go, it's a pretty nice way to build and run workflows. I combined this tooling with the idea of God to create a native, more performant, secure, and scalable version of God, in go. I called it Titan.
All it did was execute a code snippet through a docker container from a HTTP request.
1curl \2 -s \3 -X POST \4 -H "content-type:application/json" \5 -d '{"language":"python","code":"print(\"hello world\")"}' \6 http://localhost:8000/executeWhich would then output:
1hello worldDocker was used to support each language, but I realized that it was a bit of a hack. Ideally a language server would be implemented to support each language, and then the code would be executed in the language server.
The (overly) happy path
When building software, many tend to think during ideation, development, and even deployment about strictly the happy path.
The "happy path" is the path that the user takes when everything goes as expected. However, what happens when the user does something unexpected?
In Titan, the happy path was that the user would submit code their code and it would return a response. However, this assumes a lot of things went "right":
- The user's code is free of compilation errors
- The user's code doesn't crash, or use too much memory
- The user's code doesn't run indefinitely, and kill the host machine's CPU
- The user's code doesn't break out of the container
- The user's code doesn't use too much bandwidth, and bring down the server for other users
The inevitable
More often than not, written code will do something unexpected. This is natural, and as engineers, we know that better than anyone (I hope).
How do we handle these unexpected cases?
If the title of this blog post didn't give it away, the solution starts - but certainly doesn't end - with isolation.
You get the millions of users you dreamed of. Your service is thriving, and you're reaping the rewards.
However, one day, you get a report that a user's account was compromised.
Someone's account was able to delete all of the files from your server.
The security nightmare
Running untrusted code without strict sandboxing is like handing strangers the keys to your production box.
In the wild
1# Malicious as fuck lol2import os, shutil3shutil.rmtree("/")With a proper sandbox this command is confined to a temporary mount-namespace; without it the host goes up in flames.
Defense like the 2004 Pistons
Having multiple layers of defense is the absolute bare minimum in RCE services.
Each layer provides an additional security boundary, ensuring that if one fails, others will still protect your system. Think of it like concentric walls around a fortress (clash of clans, anyone?). The more layers an attacker needs to break through, the less likely they'll succeed. This "defense in depth" approach combines container technologies, kernel security features, and resource controls to create a comprehensive isolation stack:
Namespaces & cgroups
Kernel primitives that wall processes off and meter their resources
Drop capabilities
--cap-drop=ALL removes almost every privileged operation
Seccomp / AppArmor
Block dangerous syscalls (e.g., ptrace, mount)
Read-only file-system
--read-only prevents writes outside /tmp
No network
--network none stops data exfiltration
Non-root UID
Never run as root; even inside containers
Remember y'all, a single broken layer here shouldn't bring the house (server) down. Always remember that there's defense in layers.
Some approaches to execution
Bad: bare metal docker exec
1// Bad bad bad...shell-interpolation & zero limits2exec(`docker run ${lang} /bin/bash -c "${userCode}"`);This is bad because it's vulnerable to shell injection. That's a classic CVE, and it's a good example of why you shouldn't
use exec to run a command on production servers.
Better: hardened container w/ more config
1function runInSecureContainer(lang: string, code: string) {2 const dockerArgs = [3 'run', '--rm',4 '--user', '1000:1000',5 '--network', 'none',6 '--memory', '128m',7 '--pids-limit', '64',8 '--cap-drop', 'ALL',9 '--read-only',10 '--security-opt', 'seccomp=./seccomp.json',11 `${lang}-runner:latest`,12 '/bin/sh', '-c', code13 ];14
15 const proc = Bun.spawn(['docker', ...dockerArgs], {16 stdout: 'pipe',17 stderr: 'pipe'18 });19
20 return proc.stdout.text();21}Okay, we're making some progress. We're not using exec inline, so we tik off the first layer,
but remember. Docker doesn't actually isolate the container from the host machine.
So, we need to do some more work to make it somewhat isolated. We'll drop all capabilities, run the container as a non-root user, and run it in a read-only file system.
Beyond containers: microVMs & gVisor
These tools are a bit more heavy-weight than containers, but they provide a lot of additional security features. A godsend for a production environment. With firecracker, you can start a new VM for each request, and with gVisor, you can intercept syscalls in userspace - a sweet spot between containers and microVMs.
1firecracker --api-sock /tmp/fc.sock --config-file fc_config.jsonContainers share the host kernel; micro-virtual-machines give every request its own kernel without the heavyweight boot times of classic VMs.
Detecting time & memory bombs
I put together a simple simulation to visualize the different ways to detect time and memory bombs:
Sandbox Simulation
The simulation above demonstrates two critical security patterns that every sandbox system must implement:
- CPU timeouts that prevent infinite loops or computationally expensive operations from consuming all server resources
- Memory limits that catch allocation bombs before they exhaust system RAM
What's fascinating is how these protections work at different layers. The CPU timeout is essentially a watchdog timer - it doesn't actually stop the malicious code from running, it just kills the process after a threshold. Meanwhile, memory limits are enforced by the operating system's address space restrictions, preventing allocations from exceeding a pre-defined boundary.
Try experimenting with different timeout and memory values in the simulation. You'll notice that higher limits give malicious code more room to run wild, while tighter constraints offer better protection but might interfere with legitimate operations. This security-functionality balance is at the heart of sandbox design.
Of course, in code, we can represent these protections too:
1export async function runWithCpuTimeout(2 cmd: string,3 timeoutMs: number = 50004) {5 const proc = Bun.spawn(['bash', '-lc', cmd], { stdout: 'pipe', stderr: 'pipe' });6 const timer = setTimeout(() => proc.kill(), timeoutMs);7 try {8 return await proc.stdout.text();9 } finally {10 clearTimeout(timer);11 }12}Memory bombs require cgroups or prlimit to cap the process's address space:
1export async function runWithMemoryLimit(2 cmd: string,3 maxMemoryMb: number = 504) {5 const args = [6 'prlimit',7 `--as=${maxMemoryMb * 1024 * 1024}`,8 '--',9 'bash',10 '-lc',11 cmd,12 ];13 const proc = Bun.spawn(args, { stdout: 'pipe', stderr: 'pipe' });14 return await proc.stdout.text();15}Or combine both protections into one helper:
1export async function runSafely(2 cmd: string,3 timeoutMs: number = 5000,4 maxMemoryMb: number = 505) {6 const args = [7 'prlimit',8 `--as=${maxMemoryMb * 1024 * 1024}`,9 '--',10 'bash',11 '-lc',12 cmd,13 ];14 const proc = Bun.spawn(args, { stdout: 'pipe', stderr: 'pipe' });15 const timer = setTimeout(() => proc.kill(), timeoutMs);16 try {17 return await proc.stdout.text();18 } finally {19 clearTimeout(timer);20 }21}An unbounded Python process can allocate memory until the host's Out-Of-Memory (OOM) killer intervenes. A cgroup memory limit contains that failure to the sandbox.
Lessons from building NextJudge
NextJudge's judge service started as a simple exec wrapper around Docker. Production load uncovered three big issues for us:
- Cold-start latency - spinning a fresh container per submission was too slow for contests
- Resource leakage - zombie containers piled up after kernel panics
- Inconsistent outputs - different locales & runtimes produced mismatched whitespace
The fix? A pre-warmed container pool managed by a lightweight queue. Containers are cycled every N submissions or upon failure, keeping memory usage flat and latency predictable (~80 ms P95).
Let's visualize it
I built this interactive simulation to show you how a container pool works in practice:
Try adding a request to see how it works!
Request Queue (0)
Container Pool (6 available)
Completed (0)
This visualization demonstrates how a pre-warmed container pool works. Containers are reused to avoid cold starts, but need cooldown periods between uses and are blocked after reaching maximum usage limit.
It's kind of funny you know, because the container pool visualizer is directly applicable to NextJudge's sandbox environment:
How we handled resources
With some Docker magic, we handle multiple requests without needing our containers to be reinitialized each time. In NextJudge, this translates to faster execution times, as containers can quickly process multiple code submissions without the overhead of constant restarts.
Cooldown periods
These periods are used to prevent resource leaks and memory fragmentation. You can think of it like rate limiting, but for persistent containers, not requests. NextJudge uses cooldowns to limit the number of high-usage containers, especially during those mid-contest, high-demand periods when the system is under heavy load.
Automatic recycling for stability
With our lightweight messaging system, both the simulation and NextJudge's platform are able to handle bursts of traffic. We used RabbitMQ to handle bursts of submissions during contests - this was key in making our service reliable at dynamic loads.
Try experimenting with the different settings. Shorter processing times improve perceived performance but might not reflect real-world execution constraints. Similarly, increasing the max uses before recycling improves throughput but risks container state leakage or memory fragmentation over time. What surprised me about this demo was how clearly it showed the many trade-offs that come with building a secure sandbox. Each container is still fully isolated, but the pre-warming and reuse patterns eliminate the cold-start penalty that would normally make containerized code execution impractically slow for interactive applications.
Let's look at some of the key patterns from the container pool implementation, but (in code) this time:
Initialization
1type Pool struct {2 free chan *Container3 maxSize int4 warmup sync.Once5 creator func() (*Container, error)6}7
8type Container struct {9 ID string10 LastUsed time.Time11 UsageCount int12 Status string // "active", "cooling", "retired"13}14
15func NewPool(size int, newContainer func() (*Container, error)) *Pool {16 p := &Pool{17 free: make(chan *Container, size),18 maxSize: size,19 creator: newContainer,20 }21 p.warmup.Do(p.preWarm)22 return p23}Pre-warming containers at startup eliminates cold latency spikes. The sync.Once ensures we only initialize the pool once, even with concurrent access.
Acquiring a container
1func (p *Pool) Acquire(ctx context.Context) (*Container, error) {2 select {3 case c := <-p.free:4 if c.UsageCount > p.maxUsage {5 go p.Recycle(c) // Async recycling6 return p.Acquire(ctx) // Retry7 }8 return c, nil9 case <-time.After(p.timeout):10 return nil, ErrNoContainers11 case <-ctx.Done():12 return nil, ctx.Err()13 }14}As library owners, we want to make sure that we're not returning degraded containers. Health checks during acquisition prevent this - along with async recycling, it keeps the acquisition path fast.
Recycling (w/ cooldown!)
1func (p *Pool) Release(c *Container) {2 c.LastUsed = time.Now()3 c.UsageCount++4
5 if c.UsageCount >= p.maxUsage {6 go p.Recycle(c)7 return8 }9
10 select {11 case p.free <- c: // Return to pool12 default: // Pool full, retire container13 p.Retire(c)14 }15}16
17func (p *Pool) StartCooldown(c *Container) {18 time.AfterFunc(p.cooldown, func() {19 c.Status = "active"20 p.Release(c)21 })22}The cooldown mechanism here uses Go's time.AfterFunc to automatically reactivate containers after a cooling period, preventing resource leaks while maintaining pool capacity. Kinda sweet, right?
Don't just implement these protections in code. Monitor everything. Kernel OOM events, container restarts, and seccomp denials. As engineers, observability turns guesswork into actionable insights.
The performance-security trade-off
As always with these things, there's a trade-off between security and performance. This chart is a good example of that, and all that jazz:
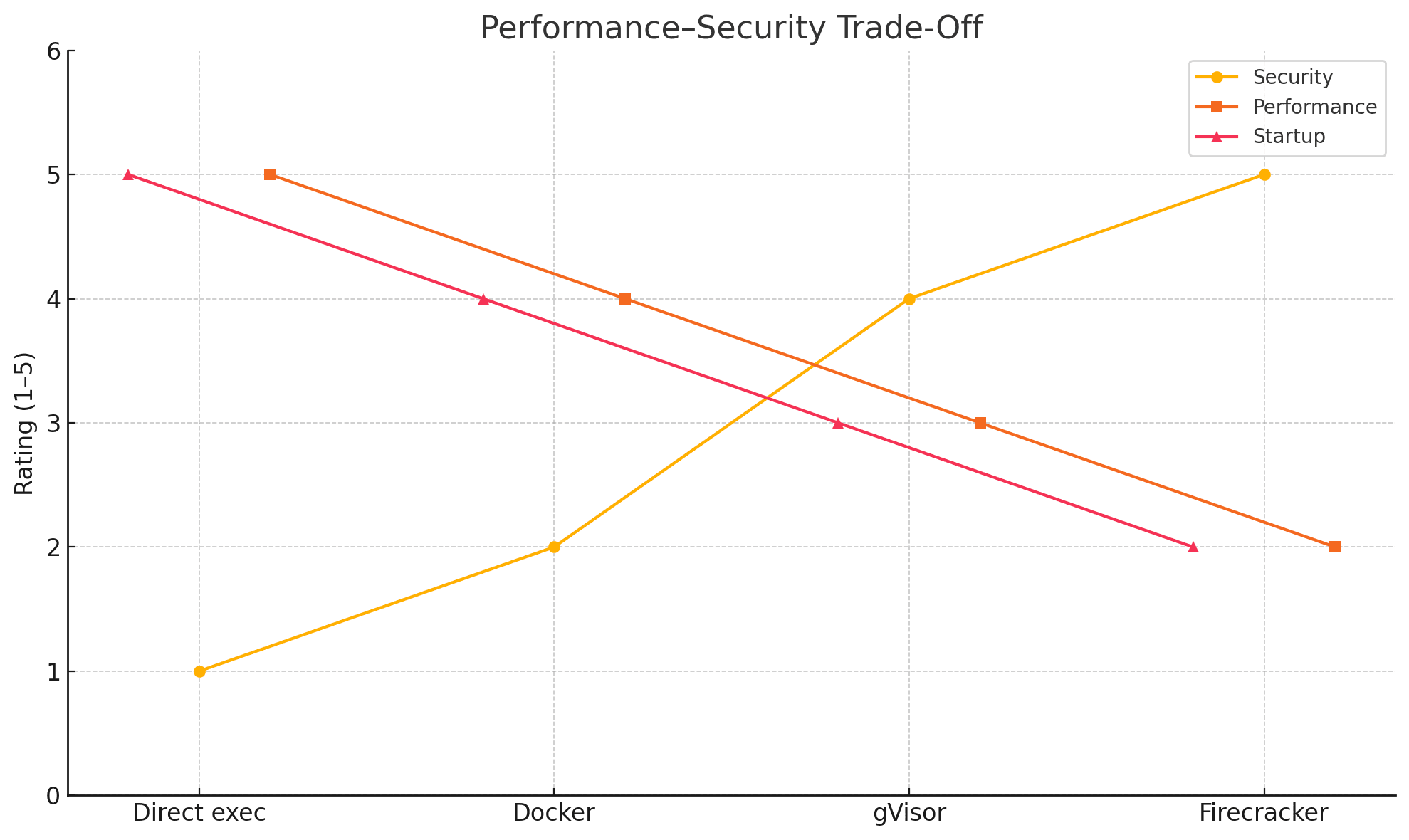
Security vs Performance
Notice how the more isolation you add, the more latency you incur. This is why it's important to measure, don't guess. It's funny because we've seen this before with so many other areas of software engineering.
By now, we know that to implement a production-grade sandbox, we need to layer multiple isolation primitives. And naturally, all of them have their own distinct trade-offs. Let's talk about it:
-
Virtual Machines (VMs)
-
These are great at emulating hardware boundaries (CPU, memory via Extended Page Tables, I/O). Their strong isolation does come at the cost of VM exits, context switches, and TLB flushes, which can introduce 10-20% throughput degradation under I/O-heavy or memory-intensive workloads.
-
I say pick these when you're in a mission-critical environment, and you need the absolute highest level of security and isolation. It'll take more engineering costs, but if you're even considering this, you're probably already spending a lot of money on your infrastructure.
-
Some of the Figma security team wrote a blog post about their server-side sandboxing, and it's a pretty interesting read. Figma: Server-side sandboxing.
-
Containers
- Linux namespaces and cgroups are used to isolate processes in user space, reusing the host kernel. While typically 2x-5x faster to start and run than VMs, cgroup enforcement still adds scheduling latency and occasional page-fault handling overhead - seccomp-filtered syscalls average 0.1-0.5 µs extra per call.
- Pick these when you need developer velocity without sacrificing basic isolation - perfect for CI/CD pipelines and microservices where you control the codebase. They're the workhorse of cloud-native development but remember: 87% of container images have high or critical vulnerabilities according to Sysdig's 2023 Cloud Native Security and Usage Report.
🚨There's some bad news though- 87% of containers contain vulnerabilities — Most images carry high-risk flaws, but focus remediation on the 15% actually loaded at runtime
- 90% of granted permissions unused — Overprivileged containers become attacker goldmines under zero-trust principles
- 59% of containers have no CPU limits — Unbounded resource claims waste 69% of allocated compute on average
- 72% live <5 minutes — Ephemeral containers demand real-time monitoring before they vanish
- Organizations overspend by over 40% — could save an average of $10 million on cloud consumption bills
- Prioritize in-use exposure — Filtering to actually loaded packages reduces fix workload by 6x
-
Seccomp-BPF filters
- Allow fine-grained syscall whitelisting in the kernel, minimizing attack surface with microsecond-level checks, but cannot prevent exploits that leverage JIT-compiled code or direct hardware instructions.
- Always use these as baseline hardening for any container environment - they're the digital equivalent of airport metal detectors. But don't stop here: seccomp policies can be bypassed through memory corruption and side-channel techniques. Read more here.
-
Dynamic instrumentation (e.g. ptrace, QEMU usermode, custom hypervisor modules)
- We love these. Hooks every syscall or instruction for deep visibility - BUT incurs 5x-20x slowdown. So they're best suited for offline analysis rather than real-time execution like in our case.
- You really only need these when analyzing third-party binaries or supply chain artifacts - think npm packages from sketchy maintainers. The performance hit becomes a feature here, forcing attackers to slow-play their exploits and get caught by your monitoring. The many approaches out there doing this with temporary VMs proves this can be done at cloud scale.
The sandbox must match the threat model: use VMs when executing highly untrusted code, containers plus seccomp for low-latency or moderate-risk workloads, and reserve heavy instrumentation for offline, critical analysis.
And please, please, please always benchmark with your workloads to quantify the security-performance balance I mentioned earlier before rolling out to your own production environments. I know the vibe coders skipped this step, but I'll say it again: benchmark.
What I took from this
A secure sandbox is not a weekend project. Attackers can target the kernel, runtime, resource accounting, and the orchestration code around it. Each boundary needs an explicit failure mode and test.
Assume every byte of user code is hostile. Paranoia is a feature, not a bug.
If you found this interesting, check out the source code of NextJudge and my sandbox runner Titan and God for real-world implementations.
Written with lessons from production meltdowns, long nights of strace, and the occasional 🍁.